我们免费从Nginx官网上下载的源码包或通过linux系统默认yum下载源中安装的nginx,都不是一个合格的商业负载均衡器。为啥这么说呢?下面我们从Nginx对负载均衡池中后端backend主机的健康检测、session会话保持、后端backend节点的监控等方面进行讲解:
使用过免费版的nginx(默认功能,没有编译加入其它第三方的健康检测模块nginx_upstream_check_module、负载均衡会话保持模块nginx-sticky-module-ng,比如淘宝的tengine)的小伙伴有没有发现nginx的upstream负载均衡池中的backend服务器组,有时很坑爹,即使某个backend不能提供正常服务了,但是nginx还是会把请求发送到这个backend,并不能把这个不正常backend服务从负载均衡池中踢出去。另一个我们说一下session会话保持功能,nginx中是通过ip_hash指令实现会话保持功能的。有很大可能使用了这个ip_hash
指令,这个负载均衡池就不能得到很好的效果。比如:我们企业搭建了一个web服务,upstream模块中的backend服务有三个服务器提供,前面用的nginx通过ip_hash进行会话绑定,但是nginx检测到客户端IP有可能来源于一个公网IP,因为企业的员工有可能都在同一个局域网内,那么这个负载均衡就没有很好的起到效果。
关于后端健康检测,我们看一下Nginx官方给的解决方案是:
Nginx 后端服务器组的配置中有5个指令,就是server指令
语法结构为:
server address [parameters];
address, 服务器地址,可以是包含端口号的IP地址(IP:Port)、域名或者以‘’unix:‘’ 为前缀用于进程间通信的 Unix Domain Socket。
parameters, 为当前服务器配置更多属性。这些属性变量包括以下内容:
weight=number,为组内服务器设置权重,权重值搞的服务器被优先用于处理请求。此时组内服务器的选择策略为加权轮叫策略。组内所有服务器的权重默认设置为1,即采用一般轮叫调度原则处理请求max_fails=number, 设置一个请求失败的次数。在一定时间范围内,当对组内某台服务器请求失败的次数超过该变量设置的值时,认为该服务器无效(down)。请求失败的各种情况与proxy_next_upstream指令的配置相匹配。默认设置为1.如果设置为0,则不使用上面的办法检查服务器是否有效。注意
- HTTP404状态不被认为是请求失败
fail_timeout=time, 有两个作用,一个是设置max_fails指令尝试请求某台组内服务器的时间,即学习max_fails 指令时提到的 “一定时间范围内”;另一个作用是在检查服务器是否有效时,如果一台服务器被认为是无效(down)的,该变量设置的时间为认为服务器无效的持续时间。在这个时间内不再检查服务器的状态,并一直认为它是无效(down)的。默认设置为10s。backup,将某台服务器标记为备用服务器,只有当正常的服务器处于无效(down)状态或者繁忙(busy)状态时,该服务器才被用来处理客户端请求。down,将某台组内服务器标记为永久的无效状态,通常与ip_hash指令配合使用。该指令在Nginx0.6.7及其以上版本中提供。
upstream backend{
server 192.168.1.80:8080 max_fails=3 fail_timeout=3s;
server 192.168.1.81:8080 max_fails=3 fail_timeout=3s;
}
上面配置的意思是:如果对backend 192.168.1.80:8080 在3s内连续产生3次请求失败,那么该后端1.80,在之后的3s内被认为是无效(down)状态,关键是我们运维人员有不知这个后端出现问题,即使知道出现了问题,也不可能在3s内搞定问题啊,那么3s之后,会再次对这个1.80发起重试max_fails次。这肯定会对客户端的访问造成服务不可达的问题,最坑爹的是我们从Nginx上压根不知到底是哪个后端节点的出现了状况,不知道哪台机宕机了或者服务假死了等原因,不能判断后端节点的状况是Nginx免费版一大弊病。这里先排出后端服务自己做的健康检测。
另一个就是nginx的链接状态和流量的统计功能,这个也适用于检查后端健康情况和当前并发链接数,这个功能社区版默认还是没有,需要在编译时加入一个官方支持的模块
--with-http_stub_status_module然后还需要在配置文件中,http块下面的某个server开启这个功能,并指定访问url
location = /ngx_status
{
stub_status on;
access_log off;
}这个页面low的要爆,我就不贴上来了,从这个low的不能在low的页面,我们不能对后端机器做出任何有利的判断
下面我们对比一下同样是免费开源的HAProxy的监控页面:

每个节点的健康状况,运行时间,宕机时间,当前连接数,最大连接数,总连接数,数据进出流量是不是一目了然,马上就可以看到这个服务器的健康状况和处理能力。能看到现在哪台服务器负担最重,可以及时调整策略。提前防范风险。
别急,我们在看看NGINX plus版的监控页面

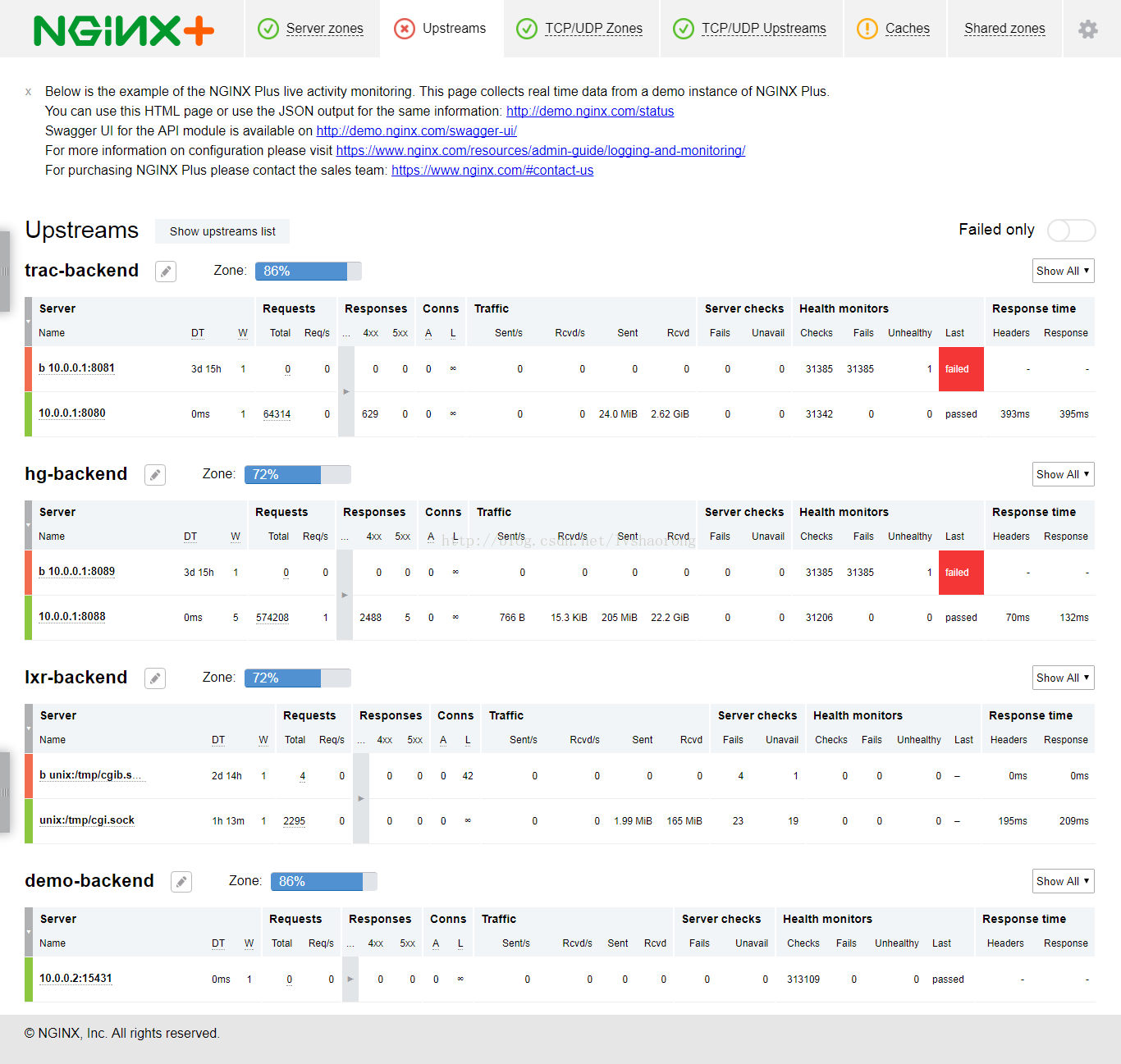
显示的内容和HAProxy差不多,但是是不是感觉更高大上了。
那么我们应该怎么办呢?要么用成熟稳定且免费开源的HAProxy做反向代理的负载均衡,要么缴纳2500美元一年购买商业版的NGINX plus。或者使用阿里巴巴为淘宝修改过的Nginx——tengine。不过tengine几乎一年才更新一次,好在一个月以前刚刚发布了2017版,支持了Nginx-1.8.1的全部特性。可是1.9之后的重要功能,比如TCP和UDP的负载均衡就没有了。
下面来看看tengine的后台监控页面
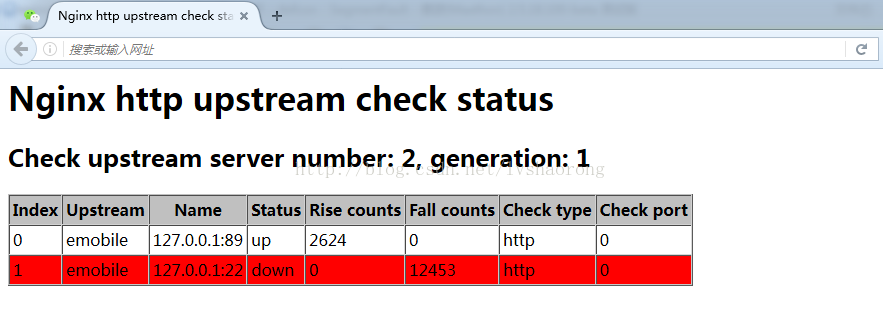
在配置文件中添加该功能的写法是:在http下面的某个server下添加
location = /status {
check_status;
access_log off;
}在这上面起码能看到哪个后端服务器宕机了,但是相对于HAProxy和Nginx plus,这个还是无法观测每台服务器的连接数和流量,不能观测负载。
那么我们运维如何选择负载均衡器呢:
- 基于Cookie的会话保持
- 可以后台监控服务器的负载状态和健康状况,主动对后端服务器进行健康检查
- 支持以最小链接数为基准的负载均衡分发策略
对HAProxy来说,上面三点全部可以实现,而且是官方全部支持,不需要什么补丁,直接可以yum源安装下载使用。
对于Tengine来说,上面三点也可以支持,但是1,3不能同时支持。也就是说如果使用了Cookie作为会话保持策略,那就不能再以最少连接数作为分发策略,只能使用轮询(round_robin),这样的话很容出现某个服务器占用超级高,然后其它服务器几乎没有负载的糟糕情况,且后台监控页面比较简陋,看不到具体每个节点的负载情况。
对于硬件负载均衡器F5或A10来说,上面3点全面支持。
但是如果公司里出现了脑残项目经理,非要使用NGINX社区版怎么办?
对于第一点,Cookie和HEAD的回话保持,我的上一篇博客NGINX基于Cookie和Header的负载均衡会话保持 里介绍了如何添加Tengine开源的nginx-sticky-module-ng实现回话保持功能,但是可惜的一点是如果使用了该回话保持方案,就不能使用最少连接数(least_conn)的分发策略,只能使用轮训(round_robin)分发策略,这样对于服务器的均衡是很不利的
对于第二点,Tengine同样开源了一个模块nginx_upstream_check_module,可以把这个模块安装到Nginx社区版进行使用。
对于第三点,社区版支持least_conn,只不过不能和cookie回话保持共用。
下面就介绍一下如何把Tengine的nginx_upstream_check_module移植到Nginx 1.12.1版本上,并添加nginx-sticky-module-ng模块实现cookie的回话保持功能。
下面就介绍一下如何把Tengine的nginx_upstream_check_module移植到Nginx 1.12.1版本上,并添加nginx-sticky-module-ng模块实现cookie的回话保持功能。大概分为如下几个步骤:
- 下载nginx_upstream_check_module源码,并对NGINX源码打补丁包
- 下载nginx-sticky-module-ng源码,并打上上面下载的nginx_upstream_check_module源码提供的补丁包
- 在configue中添加上面的两个model进行编译。
首先需要下载nginx_upstream_check_module的源码,地址:https://github.com/yaoweibin/nginx_upstream_check_module 已经添加了Nginx 1.12.1的补丁包
直接克隆这个项目到本地Nginx1.12.1源码目录下
然后下载nginx-sticky-module-ng的源码,地址:https://bitbucket.org/nginx-goodies/nginx-sticky-module-ng/downloads/
然后解压到Nginx1.12.1源码目录下,之后Nginx的源码目录结构如下:
[root@oa-app nginx-1.12.1]# ls -alt
总用量 760
drwxr-xr-x. 11 alex alex 4096 10月 25 08:38 .
drwxrwxr-x. 4 alex alex 4096 10月 24 17:31 objs
-rw-rw-r--. 1 alex alex 376 10月 24 17:30 Makefile
drwxr-xr-x 4 root root 4096 10月 24 17:26 nginx-goodies-nginx-sticky-module
-rw-r--r-- 1 root root 8060 10月 24 17:23 check_1.12.1+.patch
-rw-r--r-- 1 root root 1709 10月 24 17:23 nginx-sticky-module.patch
drwx---rwx. 17 alex alex 4096 10月 18 16:35 ..
drwxr-xr-x. 6 alex alex 4096 10月 13 16:11 auto
drwxr-xr-x. 2 alex alex 4096 10月 13 16:11 conf
drwxr-xr-x. 4 alex alex 4096 10月 13 16:11 contrib
drwxr-xr-x. 9 alex alex 4096 10月 13 16:11 src
drwxr-xr-x. 2 alex alex 4096 10月 13 16:11 html
drwxr-xr-x. 2 alex alex 4096 10月 13 16:11 man
drwxr-xr-x 6 root root 4096 8月 3 19:50 nginx_upstream_check_module-master
-rw-r--r--. 1 alex alex 277349 7月 11 21:24 CHANGES
-rw-r--r--. 1 alex alex 422542 7月 11 21:24 CHANGES.ru
-rwxr-xr-x. 1 alex alex 2481 7月 11 21:24 configure
-rw-r--r--. 1 alex alex 1397 7月 11 21:24 LICENSE
-rw-r--r--. 1 alex alex 49 7月 11 21:24 README下面要做的就是给Nginx和sticky模块打上upstream check的补丁包。
在Nginx源码目录下,执行
patch -p1 < ./nginx_upstream_check_module-master/check_1.12.1+.patch
patching file src/http/modules/ngx_http_upstream_hash_module.c
patching file src/http/modules/ngx_http_upstream_ip_hash_module.c
patching file src/http/modules/ngx_http_upstream_least_conn_module.c
patching file src/http/ngx_http_upstream_round_robin.c
patching file src/http/ngx_http_upstream_round_robin.h然后cd到nginx-sticky-module-ng源码目录下,再执行
patch -p0 < ../nginx-sticky-module.patch
patching file ngx_http_sticky_module.c
Hunk #1 succeeded at 15 with fuzz 2 (offset 5 lines).
Hunk #2 succeeded at 304 (offset 12 lines).
Hunk #3 succeeded at 330 (offset 12 lines).
Hunk #4 succeeded at 352 (offset 12 lines).最后就可以使用 make && make install 编译了
下面介绍tengine和打了tengin upstream_check补丁的社区版Nginx对于后端的健康监测有多种方式,主要用的就是TCP和HTTP方式。
默认为TCP方式,配置为
upstream emobile {
sticky;
server 127.0.0.1:22;
server 127.0.0.1:8088;
check interval=3000 rise=2 fall=5 timeout=1000 ;
}这个upstream同时配置了基于cookie的回话保持和TCP的健康检测。
这个检测每3秒执行一次,如果5次都没有成功就认定这个服务器不可达,超时时间为1秒。设定为不可达之后,请求就不会再向这个服务器发送了,但是仍然每隔3秒检测一下这个服务器的健康度,如果两次连续检查都成功就设定这个服务器为健康,然后再重新把后面的请求向这个服务器发送,实现和HAProxy一样的功能,语法也类似。
但是TCP检测有一个不好处,就是只要这个端口可以telnet通就认定为可用,如上面我把SSH的22端口和tomcat的8088端口放在一起,nginx认为两个服务器都是健康的,于是平均的向他们发送请求,所以这样总有一半的用户请求到的是404。
那么如何避免这种问题呢,可以使用HTTP模式,让NGINX主动去GET请求一个页面,如果请求的返回码为2XX,3XX就认定服务器是好用的,如下:
upstream emobile {
session_sticky;
server 127.0.0.1:22;
server 127.0.0.1:8088;
check interval=3000 rise=2 fall=5 timeout=1000 type=http;
check_http_send "GET /index.html HTTP/1.0\r\n\r\n";
check_http_expect_alive http_2xx http_3xx;
}上面的配置Nginx会每3秒钟请求一次127.0.0.1:8088/index.html这个页面,并判断HTTP状态码。因为SSH 22端口请求结果肯定是404,所以Nginx就会认为这个不可达,这样就可以避免TCP模式的缺陷。
这个check_http_send后面可以接好多种url,最常用的就是GET,还有POST和HEAD,如果你想检测特定某个页面,可以访问一下该页面然后查找access log,查看相应的请求。
下面我们扩展一下Tengine自带的两个模块ngx_http_upstream_check_module和 ngx_http_upstream_session_sticky_module
ngx_http_upstream_check_module该模块可以为Tengine提供主动式后端服务器健康检查的功能。该模块在Tengine-1.4.0版本以前没有默认开启,它需要在配置编译选项的时候开启:./configure --with-http_upstream_check_module。可是最新版本2.3.2我编译安装时,还是需要动态加入该模块的--add-module=./modules/ngx_http_upstream_check_module,貌似还是没有默认开启啊。
*Examples *
http {
upstream cluster1 {
# simple round-robin
server 192.168.0.1:80;
server 192.168.0.2:80;
check interval=3000 rise=2 fall=5 timeout=1000 type=http;
check_http_send "HEAD / HTTP/1.0\r\n\r\n";
check_http_expect_alive http_2xx http_3xx;
}
upstream cluster2 {
# simple round-robin
server 192.168.0.3:80;
server 192.168.0.4:80;
check interval=3000 rise=2 fall=5 timeout=1000 type=http;
check_keepalive_requests 100;
check_http_send "HEAD / HTTP/1.1\r\nConnection: keep-alive\r\n\r\n";
check_http_expect_alive http_2xx http_3xx;
}
server {
listen 80;
location /1 {
proxy_pass http://cluster1;
}
location /2 {
proxy_pass http://cluster2;
}
location /status {
check_status;
access_log off;
allow SOME.IP.ADD.RESS;
deny all;
}
}
}指令
Syntax: check
interval=milliseconds [fall=count] [rise=count] [timeout=milliseconds] [default_down=true|false] [type=tcp|http|ssl_hello|mysql|ajp] [port=check_port]
Default: 如果没有配置参数,默认值是:interval=30000 fall=5 rise=2 timeout=1000 default_down=true type=tcp
Context:upstream
该指令可以打开后端服务器的健康检查功能。
指令后面的参数意义是:
interval:向后端发送的健康检查包的间隔。fall(fall_count): 如果连续失败次数达到fall_count,服务器就被认为是down。rise(rise_count): 如果连续成功次数达到rise_count,服务器就被认为是up。timeout: 后端健康请求的超时时间。default_down: 设定初始时服务器的状态,如果是true,就说明默认是down的,如果是false,就是up的。默认值是true,也就是一开始服务器认为是不可用,要等健康检查包达到一定成功次数以后才会被认为是健康的。type:健康检查包的类型,现在支持以下多种类型
tcp:简单的tcp连接,如果连接成功,就说明后端正常。ssl_hello:发送一个初始的SSL hello包并接受服务器的SSL hello包。http:发送HTTP请求,通过后端的回复包的状态来判断后端是否存活。mysql: 向mysql服务器连接,通过接收服务器的greeting包来判断后端是否存活。ajp:向后端发送AJP协议的Cping包,通过接收Cpong包来判断后端是否存活。
port: 指定后端服务器的检查端口。你可以指定不同于真实服务的后端服务器的端口,比如后端提供的是443端口的应用,你可以去检查80端口的状态来判断后端健康状况。默认是0,表示跟后端server提供真实服务的端口一样。该选项出现于Tengine-1.4.0。
Syntax: check_keepalive_requests
request_num
Default:1
Context:upstream
该指令可以配置一个连接发送的请求数,其默认值为1,表示Tengine完成1次请求后即关闭连接。
Syntax: check_http_send
http_packet
Default:"GET / HTTP/1.0\r\n\r\n"
Context:upstream
该指令可以配置http健康检查包发送的请求内容。为了减少传输数据量,推荐采用"HEAD"方法。
当采用长连接进行健康检查时,需在该指令中添加keep-alive请求头,如:"HEAD / HTTP/1.1\r\nConnection: keep-alive\r\n\r\n"。
同时,在采用"GET"方法的情况下,请求uri的size不宜过大,确保可以在1个interval内传输完成,否则会被健康检查模块视为后端服务器或网络异
Syntax: check_http_expect_alive
[ http_2xx | http_3xx | http_4xx | http_5xx ]
Default:http_2xx | http_3xx
Context:upstream
该指令指定HTTP回复的成功状态,默认认为2XX和3XX的状态是健康的。
Syntax: check_shm_size
size
Default:1M
Context:http
所有的后端服务器健康检查状态都存于共享内存中,该指令可以设置共享内存的大小。默认是1M,如果你有1千台以上的服务器并在配置的时候出现了错误,就可能需要扩大该内存的大小。
Syntax: check_status
[html|csv|json]
Default:check_status html
Context:location
显示服务器的健康状态页面。该指令需要在http块中配置。
在Tengine-1.4.0以后,你可以配置显示页面的格式。支持的格式有: html、csv、 json。默认类型是html。
你也可以通过请求的参数来指定格式,假设‘/status’是你状态页面的URL, format参数改变页面的格式,比如:
/status?format=html
/status?format=csv
/status?format=json同时你也可以通过status参数来获取相同服务器状态的列表,比如:
/status?format=html&status=down
/status?format=csv&status=up下面是一个HTML状态页面的例子(server number是后端服务器的数量,generation是Nginx reload的次数。Index是服务器的索引,Upstream是在配置中upstream的名称,Name是服务器IP,Status是服务器的状态,Rise是服务器连续检查成功的次数,Fall是连续检查失败的次数,Check type是检查的方式,Check port是后端专门为健康检查设置的端口):
Nginx http upstream check status
Nginx http upstream check status
Check upstream server number: 1, generation: 3
Index
Upstream
Name
Status
Rise counts
Fall counts
Check type
Check port
0
backend
106.187.48.116:80
up
39
0
http
80
下面是csv格式页面的例子:
0,backend,106.187.48.116:80,up,46,0,http,80下面是json格式页面的例子:
{"servers": {
"total": 1,
"generation": 3,
"server": [
{"index": 0, "upstream": "backend", "name": "106.187.48.116:80", "status": "up", "rise": 58, "fall": 0, "type": "http", "port": 80}
]
}}ngx_http_upstream_session_sticky_module该模块是一个负载均衡模块,通过cookie实现客户端与后端服务器的会话保持, 在一定条件下可以保证同一个客户端访问的都是同一个后端服务器。
Example 1
# 默认配置:cookie=route mode=insert fallback=on
upstream foo {
server 192.168.0.1;
server 192.168.0.2;
session_sticky;
}
server {
location / {
proxy_pass http://foo;
}
}Example 2
#insert + indirect模式:
upstream test {
session_sticky cookie=uid domain=www.xxx.com fallback=on path=/ mode=insert option=indirect;
server 127.0.0.1:8080;
}
server {
location / {
#在insert + indirect模式或者prefix模式下需要配置session_sticky_hide_cookie
#这种模式不会将保持会话使用的cookie传给后端服务,让保持会话的cookie对后端透明
session_sticky_hide_cookie upstream=test;
proxy_pass http://test;
}
}指令
语法:session_sticky
[cookie=name] [domain=your_domain] [path=your_path] [maxage=time] [mode=insert|rewrite|prefix] [option=indirect] [maxidle=time] [maxlife=time] [fallback=on|off] [hash=plain|md5]
默认值:session_sticky cookie=route mode=insert fallback=on
上下文:upstream
说明:
本指令可以打开会话保持的功能,下面是具体的参数:
cookie设置用来记录会话的cookie名称domain设置cookie作用的域名,默认不设置path设置cookie作用的URL路径,默认不设置maxage设置cookie的生存期,默认不设置,即为session cookie,浏览器关闭即失效mode设置cookie的模式:- insert: 在回复中本模块通过Set-Cookie头直接插入相应名称的cookie。
- prefix: 不会生成新的cookie,但会在响应的cookie值前面加上特定的前缀,当浏览器带着这个有特定标识的cookie再次请求时,模块在传给后端服务前先删除加入的前缀,后端服务拿到的还是原来的cookie值,这些动作对后端透明。如:”Cookie: NAME=SRV~VALUE”。
- rewrite: 使用服务端标识覆盖后端设置的用于session sticky的cookie。如果后端服务在响应头中没有设置该cookie,则认为该请求不需要进行session sticky,使用这种模式,后端服务可以控制哪些请求需要sesstion sticky,哪些请求不需要。
option设置用于session sticky的cookie的选项,可设置成indirect或direct。indirect不会将session sticky的cookie传送给后端服务,该cookie对后端应用完全透明。direct则与indirect相反。maxidle设置session cookie的最长空闲的超时时间maxlife设置session cookie的最长生存期fallback设置是否重试其他机器,当sticky的后端机器挂了以后,是否需要尝试其他机器hash设置cookie中server标识是用明文还是使用md5值,默认使用md5
语法: session_sticky_hide_cookie upstream=name;
默认值: none
上下文: server, location
说明:
配合proxy_pass指令使用。用于在insert+indirect模式和prefix模式下删除请求用于session sticky的cookie,这样就不会将该cookie传递给后端服务。upstream表示需要进行操作的upstream名称。



